
 by Ricardo Henrique-Araújo, MD, MSc; Flávia L. Osório, PhD; Mônica Gonçalves Ribeiro, MD, PhD; Ivandro Soares Monteiro, PhD; Janet B. W. Williams, PhD; Amir Kalali, MD; José Alexandre Crippa, MD, PhD; and irismar Reis de Oliveira, MD, PhD
by Ricardo Henrique-Araújo, MD, MSc; Flávia L. Osório, PhD; Mônica Gonçalves Ribeiro, MD, PhD; Ivandro Soares Monteiro, PhD; Janet B. W. Williams, PhD; Amir Kalali, MD; José Alexandre Crippa, MD, PhD; and irismar Reis de Oliveira, MD, PhD
Dr. Henrique-Araújo is from the Institute of Health Sciences, Federal University of Bahia, Salvador, and Nova Esperança Medical School, João Pessoa, Brazil; Dr. Osório is from the Department of Neuroscience and Behavior, State University of São Paulo, Ribeirão Preto, and the National Institute of Science and Technology (INCT) for Translational Medicine, Brazil; Dr. Ribeiro is from Sanatório São Paulo, Salvador, Brazil; Dr. Monteiro is from Orasi Institute, Porto, Portugal; Dr. Williams is from MedAvante Inc. and is a Professor Emerita at Columbia University, New York, New York, USA; Dr. Kalali is from Quintiles Inc., and the University of California, San Diego, California, USA; Dr. Crippa is from the Department of Neuroscience and Behavior, State University of São Paulo, Ribeirão Preto, Brazil, and the National Institute of Science and Technology (INCT) for Translational Medicine, Brazil; Dr. de Oliveira is from the Department of Neurosciences and Mental Health and the Institute of Health Sciences, Federal University of Bahia, Salvador, and Sanatório São Paulo, Salvador, Brazil.
Innov Clin Neurosci. 2014;11(7–8):10–18
Funding: There was no funding for the development and writing of this article.
Financial Disclosures: None of the authors have a conflict of interest in the conduct and reporting of this study.
Key words: Depression, transcultural adaptation, GRID Hamilton rating scale for depression (GRID-HAMD), reproducibility of results
Abstract: GRID-HAMD is a semi-structured interview guide developed to overcome flaws in HAM-D, and has been incorporated into an increasing number of studies.
Objectives: Carry out the transcultural adaptation of GRID-HAMD into the Brazilian Portuguese language, evaluate the inter-rater reliability of this instrument and the training impact upon this measure, and verify the raters’ opinions of said instrument.
Methods: The transcultural adaptation was conducted by appropriate methodology. The measurement of inter-rater reliability was done by way of videos that were evaluated by 85 professionals before and after training for the use of this instrument.
Results: The intraclass correlation coefficient (ICC) remained between 0.76 and 0.90 for GRID-HAMD-21 and between 0.72 and 0.91 for GRID-HAMD-17. The training did not have an impact on the ICC, except for a few groups of participants with a lower level of experience. Most of the participants showed high acceptance of GRID-HAMD, when compared to other versions of HAM-D.
Conclusion: The scale presented adequate inter-rater reliability even before training began. Training did not have an impact on this measure, except for a few groups with less experience. GRID-HAMD received favorable opinions from most of the participants.
Introduction
According to the National Comorbidity Survey Replication (NCS-R), the prevalence of lifetime major depressive disorder (MDD) is estimated at 16.9 percent for the general population—20.2 percent for female individuals and 13.2 percent for male.[1] Currently, MDD is the second greatest cause of impairment worldwide in individuals between the ages of 15 and 44, and in the projections for the year 2020, depression is mentioned as the second largest cause of worldwide impairment, in both genders and among all the age brackets.[2-5]
The Hamilton Rating Scale for Depression (HAM-D) is the instrument most widely used to measure severity of the depression and the clinical changes due to therapeutic interventions,[6-8] and has been considered an international standard for this purpose.[9-12]
In the scientific literature, there has been criticism pointed at HAM-D: for example, a systematic review pointed out that, in general, the low inter-rater reliability of HAM-D has been the most disquieting factor regarding this scale.[9] Snaith[13] had already reported some of these problems and Hamilton[14] himself acknowledged that there was room for improvement in the scale he developed.
The Depression Rating Scale Standardization Team (DRSST) was a group formed by researchers whose aim was to standardize the administration and scoring of HAM-D without significantly altering the original intent of the items on this scale or the scoring profile.[15-17] In a meeting held in 2000, the members of this group began the project of creating a standardized version, with the final result being the development of GRID-HAMD,[18] a modified version of HAM-D that presented three components: a GRID scoring system (scores intensity and frequency independently, to obtain the severity score, using a chart with vertical intensity measurements and horizontal frequency ones); scoring conventions with detailed descriptions of the anchors and behavior models; and lastly, a semi-structured interview guide based on the SIGH-D.[12,17,19,20]
The GRID-HAMD was originally developed in the English language, having been later translated into Japanese, in a study that also evaluated the inter-rater reliability of the scale.[12] To this date, there is still no publication in the literature of the Brazilian Portuguese version of this instrument. This study has as its objective the cultural adaptation of GRID-HAMD for this cultural context as well as the evaluation of the inter-rater reliability of this version.
METHODS
Ethics aspects. This research was submitted and approved by the Research Ethics Committee of Maternity Hospital Climério de Oliveira at the Federal University of Bahia before the start of the interview recordings and data collection.
Transcultural adaptation of GRID-HAMD. Amir Kalali, one of the developers of GRID-HAMD, was contacted to authorize the translation and validation of this instrument in the Brazilian Portuguese language. The original GRID-HAMD, in English, was submitted to be translated into Brazilian Portuguese by two Brazilian researchers who participated in this study, both fluent in English, generating the initial translation. Following this, the first version in Brazilian Portuguese was submitted to the process of back translation, carried out by a translator who was fluent in both languages, blind to the original GRID-HAMD instrument, and aware of the research objectives. This new version was sent to Janet Williams, one of the authors of the original instrument in English, in order to have her verify the credibility of the text with regard to the original scale. Following her observations about the translation, the two Brazilian researchers who did the initial translation made the necessary modifications, taking into consideration the semantic incompatibilities pointed out by the author. Once more, the instrument was sent to the translator, afterwards being sent to Williams. This process was repeated three times until the final version of GRID-HAMD was achieved, now translated into Brazilian Portuguese.
Training for utilizing GRID-HAMD. The training period brought together 115 mental health clinicians, among them psychiatrists, psychiatry residents, physicians with experience in evaluating depressed patients, clinical psychologists, and a nurse. Some of the participants had previous experience in applying HAM-D and others had never administered this instrument. All the participants who took part in the training sessions were involved in this study, so that the 30 people who enrolled at the first center made up the pilot study, and the 85 who enrolled at the other two research centers made up the sample itself; that is, they generated the results that were submitted for analysis.
Pilot study. Thirty professionals participated in the pilot study. During this stage, the researchers taking part in this study, along with the participants, detected aspects in the training that could create biases; therefore, these aspects were modified in order for them to become suitable for the objectives of this research. The results produced by the evaluators of the pilot study were excluded from the final data analysis.
Instruments and materials. Brazilian version of GRID-HAMD. This version was obtained by way of the process of transcultural adaptation for Brazilian Portuguese from the original version proposed by DRSST,[18] as described above.
Self-report questionnaires. One questionnaire involved questions about professional experience, research experience, and experience in using scales with regard to applying HAM-D. Another self-report questionnaire involved items related to the participants’ personal evaluation of different aspects of GRID-HAMD, such as usefulness in research, ease of its use, necessary time for the administration, and needed improvement of the conventions with regard to those of HAM-D and of SIGH-D.
Videos. Five videos were used that contained administration, in Brazilian Portuguese, of the semi-structured GRID-HAMD interview. Those interviewed were patients with clinical pictures of depression, having either MDD (single episode or recurring), dysthymic disorder (DD) or bipolar disorder (BD), according to the Diagnostic and Statistical Manual of Mental Disorders, Fourth Edition, Text Revision (DSM-IV-TR) criteria. Filming was carried out after obtaining signed consent forms authorizing taping and use of images, and the videos were produced specifically for the purpose of this training. The duration of each video varied between 29 and 38 minutes, and the four videos used to generate reliability data (Videos 1, 2, 3, and 4) scored 29, 40, 29, and 20 points, respectively, from the consensus of the specialist researchers.
Training script. During the classes, the participants were all in the same room, later being separated into two groups only at the time of evaluation of the pair of videos. As the difficulties in evaluation could differ between the videos, the participants were randomly divided into two groups, A or B, and each group first watched the pair of videos, so that one group could not see what the other group was watching at that time. The interviews were scored individually, using the GRID-HAMD. Prior to the evaluation of any of the pair of videos, the raters were given a period of 30 minutes to individually read through the items, the Instructions for Use and the GRID-HAMD General Guidelines. At the end of the training session, each group watched the pair of videos that they knew nothing about and also gave them a score using GRID-HAMD. In this way, all four videos were used as a substratum for impact analysis of the training (Videos 1, 2, 3, and 4) and were evaluated either before or after the training session by one of the participating groups. Video 5 was used for demonstration purposes during the course of training. This course was carried out in two research centers and lasted eight hours divided into two shifts of the same day following the schematic script shown in Figure 1.

Data analysis. The data were collected from the information filled out by the training participants. Data referring to the raters’ professional and academic profiles and the video scores were analyzed and correlated using 17.0 version of SPSS Statistics Software.[21] The inter-rater reliability was estimated by ANOVA Intraclass Correlation Coefficient (ICC).
For the degree of agreement categories and the ICC values, we used as our basis the study of Landis and Koch.[22]
RESULTS
In the attained sample, 56 participants (65.9%) were clinical psychologists, 27 (31.8%) were physicians (psychiatrists or otherwise), and one (1.2%) was a nurse (1 professional did not inform about a college degree); regarding length of time since graduating, 43 (50.6%) had up to five years and 41 (48.2%) had more than five since graduation. As to graduate degrees, 13 (15.3%) of the participants had obtained their Master’s degree, 35 (41.2%) had concluded specialization courses or medical residencies, and two (2.4%) had obtained a PhD; 21 (24.7%) of the professionals had little or no clinical experience, while 61 (71.8%) had moderate or extensive clinical experience. Regarding the use of research scales, 53 (62.4%) had little or no experience, while 23 (27.1%) had moderate or extensive experience; with regard to a clinical context, 50 (58.8%) had little or no experience and 23 (27.1%) had moderate or extensive experience. Referring specifically to having experience in using HAM-D, 62 (72.9%) had never administered this instrument, while 22 (25.9%) had administered it at least once.
Table 1 shows that, considering the sample as a whole, the ICC values obtained from the GRID-HAMD-21 were maintained between 0.76 and 0.90, and, for the GRID-HAMD-17, they were between 0.72 and 0.91, considering the evaluation before and after the training session. The p-value was greater than 0.05 in all the comparisons, showing that there was no statistically significant difference, when comparing the response agreement of the total scores of GRID-HAMD-21 for all the videos evaluated, before and after training took place. Thus, the inter-rater reliability for all the videos was considered adequate, and there was no training impact upon this measure.
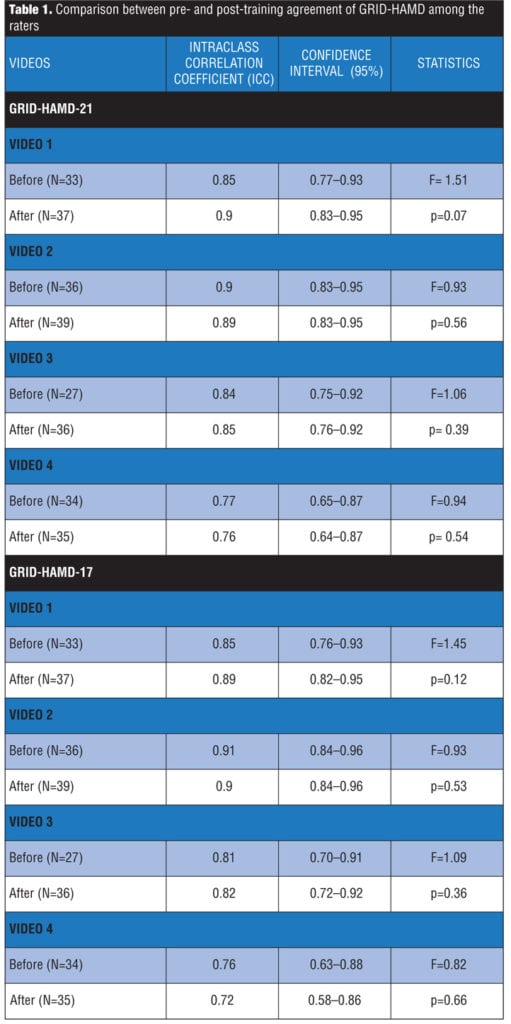
Table 2 shows the estimate of the inter-rater reliability from the comparative analysis among participants who never administered the HAM-D and those who already had, at least one time. In all the table analyses, there was no statistically significant difference between the two groups (p>0.05), except upon comparing Video 3 after the training period, showing that only in this case did the group of experienced raters in HAM-D reach a higher reliability compared with the inexperienced rater group (p?0.05).

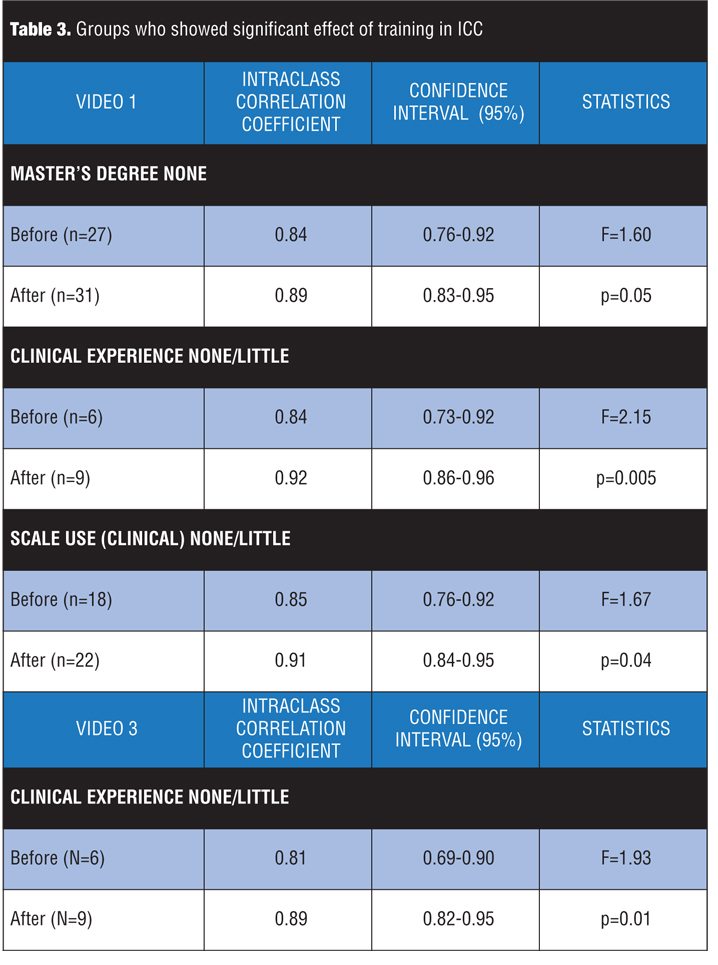
The inter-rater reliability was also analyzed from participant grouping according to their professional and academic experience. For most of the groups, there was no statistically significant difference between the agreement of total scoring of the GRID-HAMD-21 comparing the group that evaluated the video before and the one that evaluated it after training; however, for some rater groups with less clinical or academic experience, the training effect upon the inter-rater reliability was greater, showing the increase in the ICC measure in three comparisons for Video 1 and in one comparison for Video 3 (Table 3).
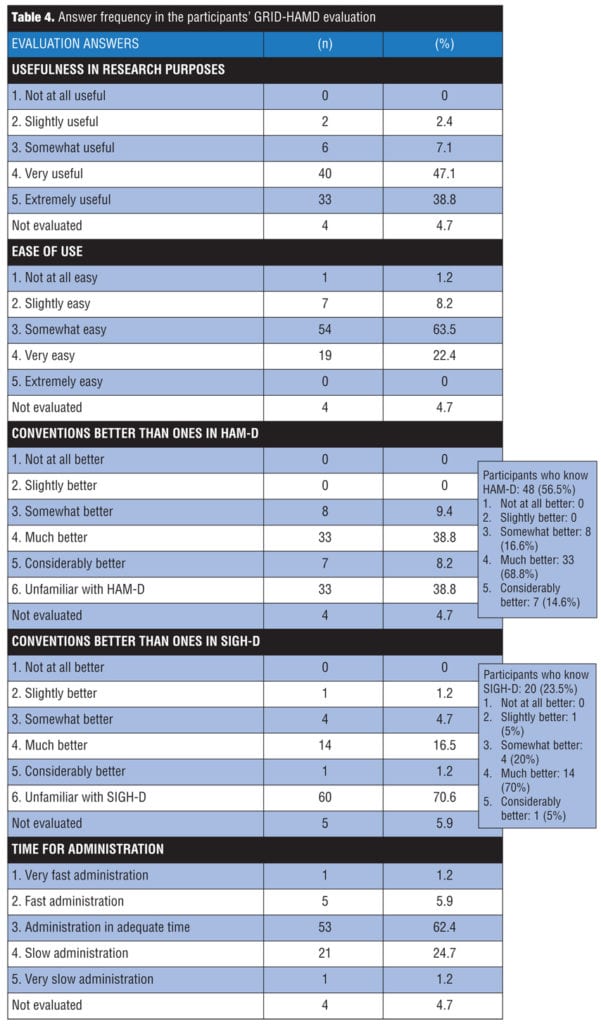
As Table 4 shows, the majority of the training participants considered the GRID-HAMD a “very useful” or “extremely useful” tool for the purpose of research, “somewhat easy” or “very easy” to use, and having an “administration in adequate time.”
Further analysis revealed that among those who were already familiar with HAM-D (48 participants), most of them thought the GRID-HAMD presented “much better” (68.8%) or “considerably better” (14.6%) conventions than the original instrument; and among those who knew the SIGH-D (20 participants), the majority considered the GRID-HAMD conventions “much better” (70%) or “considerably better (5%) than the ones from that structured interview guide.
DISCUSSION
The transcultural adaptation of the GRID-HAMD took place within the context of Brazilian culture. Even when considering that other countries share the Portuguese language as their official language, one should take into account that there are socio-cultural nuances that interfere in the use of the language.[23] Thus, it cannot be said that the scale is culturally adapted to be used in other lusophone countries other than Brazil. This version is available without cost for its use within a clinical and research context and can be requested from the authors.
The study developed by Tabuse et al[12] with the GRID-HAMD, translated into Japanese, does not present data on most of the information that refers to the sample presented in this work. With regard to the experience in the use of the HAM-D, the sample of the Japanese study is made up of 28.6 percent of people with no experience, 24.3 percent of those who administered it between one and five times, 47.1 percent of the participants who administered it six or more times without training, and 22.9 percent who administered it six or more times, having had formal training. The sample from said study is mostly made up of individuals with large experience in using the HAM-D, while this present study has a marked predominance of people who had no experience in administering this scale. One other detail is that, in both studies, among those who administered it six or more times, it is not known how many more times over six it did in fact occur.
The results show that, for all four videos, the GRID-HAMD-21 presented ICCs for the total score, varying between 0.76 and 0.90, being considered almost perfect for Videos 1, 2, and 3, and substantial for Video 4. With regard to GRID-HAMD-17, the results were quite similar, with ICCs varying between 0.72 and 0.91, maintaining the same categories and closeness of agreement as those of the GRID-HAMD-21.[22] The close approximation of the values between both formulations of the GRID-HAMD (17 and 21 items) allowed that the results using a scale of 21 items (for separating the groups into levels of experience) be compared to other studies using the 17-item scale.
The ICC results with regard to the total GRID-HAMD score, found by Williams et al[17] in a pilot study, remained similar to those of the present study and alternated between 0.75 and 0.89. The above-mentioned authors, in a validation and reliability study, found ICC values of 0.94 (as high as the ones in SIGH-D and significantly higher than Guy’s version for HAM-D). The results from Tabuse et al[12] showed higher ICC values for GRID-HAMD-17 in Japanese (the values found remained between 0.93 and 0.99—“almost perfect”), despite the fact that, in the present study, the values were also considered “almost perfect,” except for Video 4, the values of which only reached the level of the category below—“substantial.” This study, as well as the Japanese study, agreed upon the fact that, even before training, the ICC had already attained adequate values and that the training did not have an impact on this measure (p>0.05 for all the videos). This finding suggests that the utilization instructions, the semi-structured interview guideline and the convention manual are efficient enough to promote an adequate inter-rater reliability for this instrument without the evaluators necessarily having to go through the training.
Notwithstanding, this study showed that for less experienced evaluators, the training can have an impact on this measure and should be assigned. The impact of the training was not rated with regard to other reliability measures or validity measures.
In this study, the interviews were carried out with real patients, while Tabuse et al[12] utilized videos recorded by actors. Using real patients for this objective could have caused inherent difficulties, most of which are also present in clinical and research contexts: difficulty in communication, being camera shy, presence of comorbidities, answer ambivalence, and memory bias, among others.
Still with regard to making the videos, the Japanese study used the same patient in each pair of videos, at different times of treatment, which could have at least furnished a referential standard for evaluating the subsequent videos, especially in relation to the items that were scored by observation and not by what was reported (Items 8 and 9). The present study may have counted on the difficulty involved in evaluating a different patient in each one of the videos, which is much closer to the reality of actual clinical trials, where the same patient may be evaluated by different researchers at different times, depending on the availability of the researcher for that task at every time. Moreover, it is also possible that there were differences in the level of complexity of the cases used by the two studies (the total scores for the videos of the present study point to this supposition, possibly with a larger number of individual items scoring zero in that study, to the detriment of this one: in the Japanese study, the videos totaled 26, 10, 37, and 19 points versus 29, 40, 29, and 20 in this study).
Although our study presented methodological characteristics that could have made the video evaluations more difficult in comparison with the study of Tabuse et al,[12] the inter-rater reliability remained at almost perfect levels, at least in Videos 1, 2, and 3. These methodological characteristics simulate a reality that is much closer to the one found in research environments, giving this fact importance in raising the perception that the GRID-HAMD continues to be an instrument with adequate inter-rater reliability in the presence of adversities frequently found in clinical trials. Video 4 of our study presented values a bit lower, diverging from the three others, which might suggest that there could have been difficulties inherent to the video itself.
In the study of the HAM-D publication in 1960, Hamilton[14] presented inter-rater reliability rates between 0.84 and 0.90, for the 17-item scale he had developed. Bagby et al,[9] by way of a systematic revision, found ICC values between 0.46 and 0.99, giving evidence that HAM-D can only show moderate inter-rater reliability for the total score. Until the present time, all the studies that evaluated this measure for GRID-HAMD found values considered to be adequate for the total score, with the majority of the results being almost perfect and only a few considered substantial, with no results falling below this category.[12,17]
After dividing up the training participants into two groups, according to having or not having previous experience in the use of HAM-D, the ICC values were considered almost perfect for Videos 1, 2, and 3, and almost perfect or substantial for video four. The results of this measure and the p-value demonstrated that this characteristic did not promote an improvement in the inter-rater reliability in seven of the eight comparisons that were carried out. The ICC presented a statistically significant increase only for Video 3, when evaluated after the training took place; however, both measures remained at almost perfect levels. This analysis points out that GRID-HAMD does not necessarily demand that researchers have any previous experience in HAM-D in order to obtain adequate inter-rater reliability. This characteristic of said research instrument is quite advantageous, for some authors had already mentioned the difference in levels of experience that commonly exists among researchers in the same clinical trial.[16,24]
When the participants were grouped according to characteristics of academic training or experience, it was observed that, for most of the groups, there was no statistically significant difference when they were compared between the evaluations before and after training (they presented p>0.05), apart from the exceptions shown in Table 3.
In a general sense, in all the groups of experienced professionals and in many of the ones with professionals having less experience, the training did not affect the inter-rater reliability, except for the groups summarized above, which share the fact of having individuals with a lower degree of experience.
Among the raters, 85.9 percent considered the use of GRID-HAMD “somewhat easy” or “very easy.” Only one participant considered the scale “not at all easy” to be used; 83.4 percent of the raters familiar with HAM-D were of the opinion that the GRID-HAMD conventions were “much better” or “considerably better” than the original instrument, and 75 percent of those familiar with SIGH-D considered the GRID-HAMD conventions “much better” or “considerably better”?than those of that structured interview guide. The pilot-study of Williams et al17 showed that 75 percent of the raters referred to the GRID-HAMD as “easy” or “very easy” to be used and that 100 percent of said raters considered the conventions of this scale “somewhat better” or “much better” than the scale standards that they used in their research centers. Furthermore, 85.9 percent of those in our sample were of the opinion that the GRID-HAMD is a very useful or extremely useful tool for research purposes. As to the time of administration, 62.4 percent of our sample considered it to be adequate.
A few limitations were identified in this study. The inter-rater reliability was not evaluated for the individual items of the GRID-HAMD translated into Brazilian Portuguese, which originated from statistical difficulties to attain this type of analysis. Another limit is regarding the data of the raters’ opinion about the usefulness of the GRID-HAMD for research purposes, for the majority had none or very little experience in the use of scales in a research context, which suggests that they did not have at their disposal enough of a theoretical and practical framework in order to give opinions concerning this aspect. Lastly, among the videos evaluated, there is no evidence of depression in the range of mild intensity, since all the scores were between 20 and 40 points. This last characteristic, despite distancing the interviewed patients (videos) from broader clinical populations, from a symptomatic intensity perspective, makes this sample quite representative of those comprising clinical trials, and, for this reason, the study objective continues being met.
In future studies, it might be useful to duplicate this study with the carried out procedure, in order to expand the size of the sample, which would contribute to confirm and validate the obtained results. This study evaluated the inter-rater reliability with a team of raters. Future studies should test this measure with independent raters, in order to come closer to the experience of the real environment of clinical trials.
CONCLUSION
GRID-HAMD was adequately adapted for the Brazilian Portuguese language. The scale presented adequate inter-rater reliability even before training began. The training did not have a relevant impact on the ICC, except for a few groups with less experience, for which we recommend the GRID-HAMD administration by trained professionals. GRID-HAMD was evaluated by the training participants regarding several important aspects and received favorable opinions from most of the said participants.
References
1. Harvard School of Medicine. National Comorbidity Survey (NCS) and National Comorbidity Survey Replication (NCS-R). Boston, 2005. Available at: http://www.hcp.med.harvard.edu/ncs/index.php. Accessed February 16, 2012.
2. Branco BM, Fernandes FN, Powell VMB, et al. Depressão: considerações diagnósticas e epidemiológicas. In: Lacerda ALT, Quarantini LC, Miranda-Scippa AMA, Del Porto JA (eds). Depressão: do neurônio ao funcionamento social. Porto Alegre: Artmed; 2009:13–26.
3. Chapman DP, Perry GS. Depression as a major component of public health for older adults. Prev Chronic Dis. 2008;5(1). Available at: http://www.cdc.gov/pcd/issues/2008/ jan/07_ 0150.htm. Accessed April 09, 2013.
4. Pan AW, Chan, PYS, Chung L, et al. Quality of life in depression: predictive models. Quality of Life Research. 2006;15(1):39–48.
5. World Health Organization. Mental health, new understanding, new hope. The World Health Report. Geneva, 2001. Available at: http://www.who.int/whr/2001/en. Accessed April 28, 2013.
6. Corruble E, Hardy P. Why the Hamilton Depression Rating Scale endures. Am J Psychiatry. 2005;162(12):2394.
7. Enns MW, Larsen DK, Cox BJ. Discrepancies between self and observer ratings of depression: the relationship to demographic, clinical and personality variables. J Affect Disord. 2000;60(1):33–41.
8. Furukawa TA, Streiner DL, Azuma H et al. Cross-cultural equivalence in depression assessment: Japan-Europe-North America study. Acta Psychiatr Scand. 2005;112(4):279–285.
9. Bagby RM, Ryder AG, Schuller DR, Marshall MB. The Hamilton Depression Rating Scale: Has the gold standard become a lead weight? Am J Psychiatry. 2004;161(12):2163–2177.
10. Iannuzzo RW, Jaeger J, Goldberg JF, et al. Development and reliability of the HAM-D/MADRS Interview: an integrated depression symptom rating scale. Psychiatry Res. 2006;145(1):21–37.
11. Kriston L, Von Wolff A. Not as golden as standards should be: interpretation of the Hamilton Rating Scale for Depression. J Affect Disord. 2011;128(1-2):175–177.
12. Tabuse H, Kalali A, Azuma H, et al. The new GRID Hamilton Rating Scale for Depression demonstrates excellent inter-rater reliability for inexperienced and experienced raters before and after training. Psychiatry Res. 2007;153(1):61–67.
13. Snaith RP. Present use of the Hamilton Depression Rating Scale: observations on method of assessment in research of depressive disorders. Br J Psychiatry. 1996;168(5):594–597.
14. Hamilton M. A rating scale for depression. J Neurol Neurosurg Psychiatry. 1960;23:56–62.
15. Gotlib IH, Hammen CL. Handbook of Depression. 2nd ed. New York: Guilford Press, 2010:46–47.
16. Williams JBW. Standardizing the Hamilton Depression Rating Scale: past, present and future. Eur Arch Psychiatry Clin Neurosci. 2001;251(suppl. 2):II6–II12.
17. Williams JBW, Kobak KA, Bech P, et al. The GRID-HAMD: standardization of the Hamilton Depression Rating Scale. Int Clin Psychopharmacol. 2008;23(3):120–129.
18. Depression Rating Scale Standardization Team (DRSST). GRID-HAMD-17, GRID-HAMD-21: Structured Interview Guide. San Diego, International Society for CNS Drug Development, 2003.
19. Williams JBW. A Structured Interview Guide for the Hamilton Depression Rating Scale. Arch Gen Psychiatry. 1988;45(8):742–747.
20. Andrews LW. Encyclopedia of depression. vol. 1. Santa Barbara: Greenwood, 2010:229–231.
21. SPSS for Windows. version 17.0. Chicago: SPSS Inc., 2008.
22. Landis JR, Koch GG. The measurement of observer agreement for categorical data. Biometrics. 1977;33(1):159–174.
23. Schimitt RL, Benedito ICR, Rocha BC, et al. Adaptação transcultural da versão brasileira da escala Social Rhythm Metric-17 (SEM-17) para a população angolana. Rev Psiquiatr Rio Gd Sul. 2011;33(1):28–34.
24. Müller MJ, Dragicevic A. Standardized rater training for the Hamilton Depression Rating Scale (HAM-D-17) in psychiatric novices. J Affect Disord. 2003;77(1):65–69.